2025-02-04 18:57

![]()
2月4日凌晨,三方基準測試平臺Chatbot Arena公布了最新的大模型盲測榜單,一周前剛發(fā)布的Qwen2.5-Max超越DeepSeek V3、o1-mini和Claude-3.5-Sonnet等模型,以1332分位列全球第七名,也是非推理類的中國大模型冠軍。同時,Qwen2.5-Max在數(shù)學和編程等單項能力上排名第一,在硬提示(Hard prompts)方面排名第二。
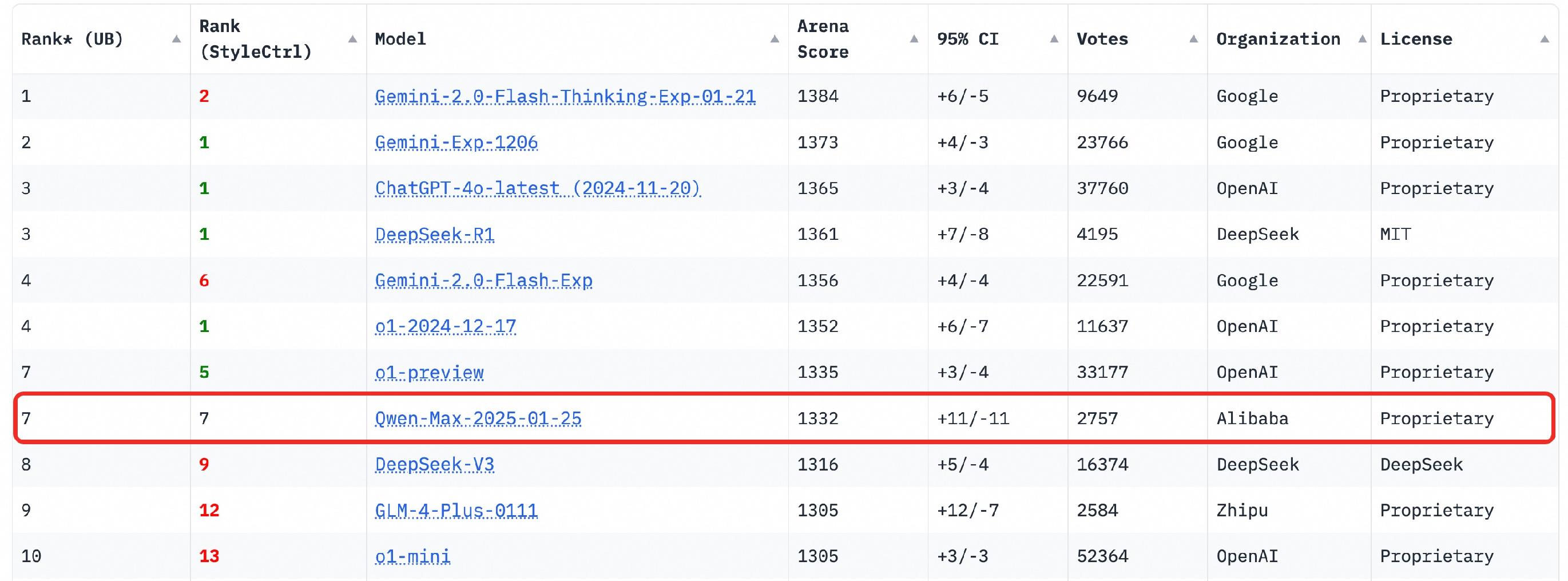
截圖自https://lmarena.ai/?leaderboard
據(jù)了解,Chatbot Arena是由LMSYS Org推出的大模型性能測試平臺,目前集成了190多種模型。該榜單采用匿名方式將大模型兩兩組隊,交給用戶進行盲測,用戶根據(jù)真實對話體驗對模型能力進行投票。因此,Chatbot Arena LLM Leaderboard成為業(yè)界公認的最公正、最權(quán)威榜單之一,也是全球頂級大模型的最重要競技場。
ChatBot Arena官方評價稱:阿里巴巴的Qwen2.5-Max在多個領(lǐng)域表現(xiàn)強勁,特別是專業(yè)技術(shù)向的(編程、數(shù)學、硬提示等)。
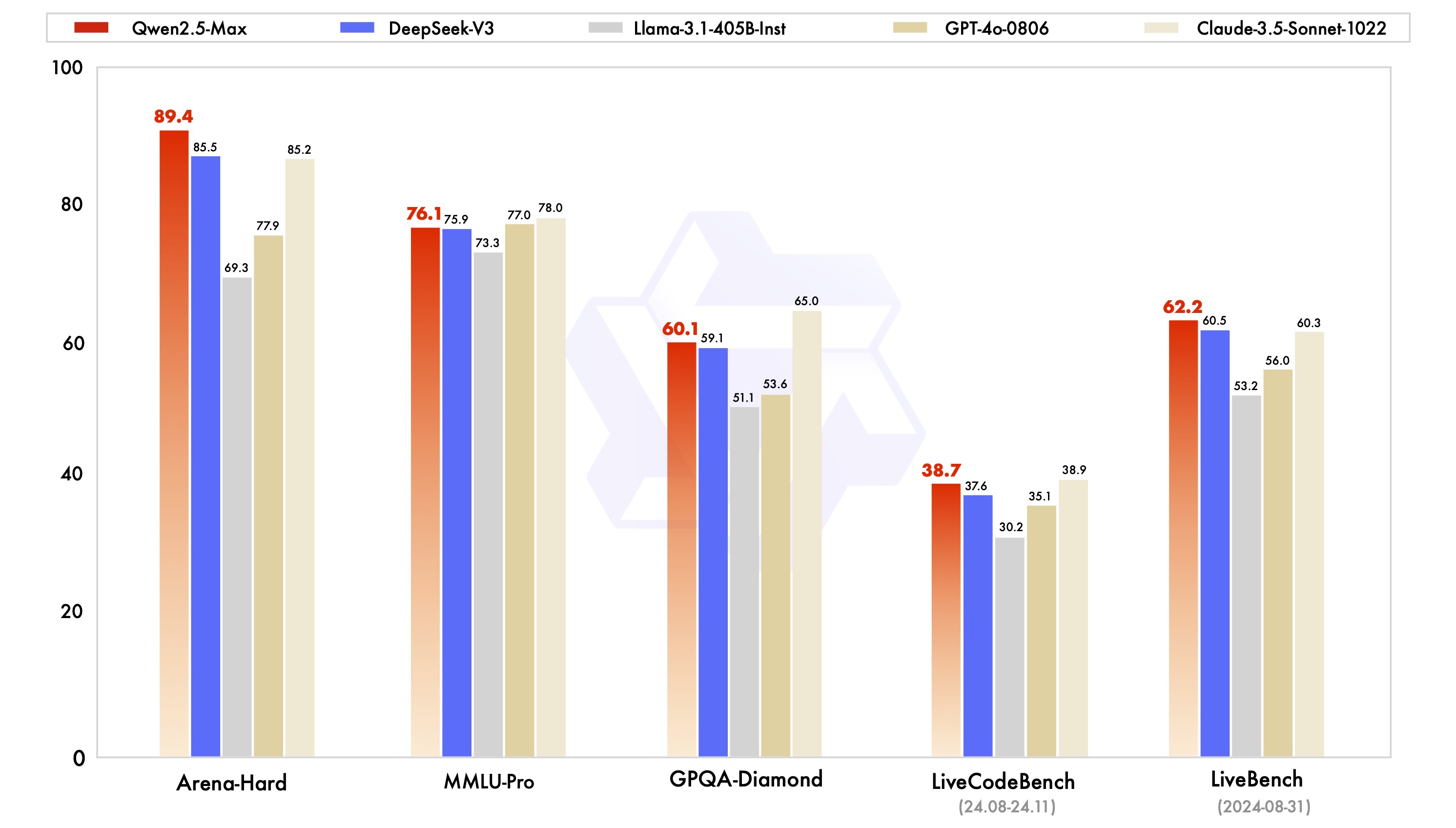
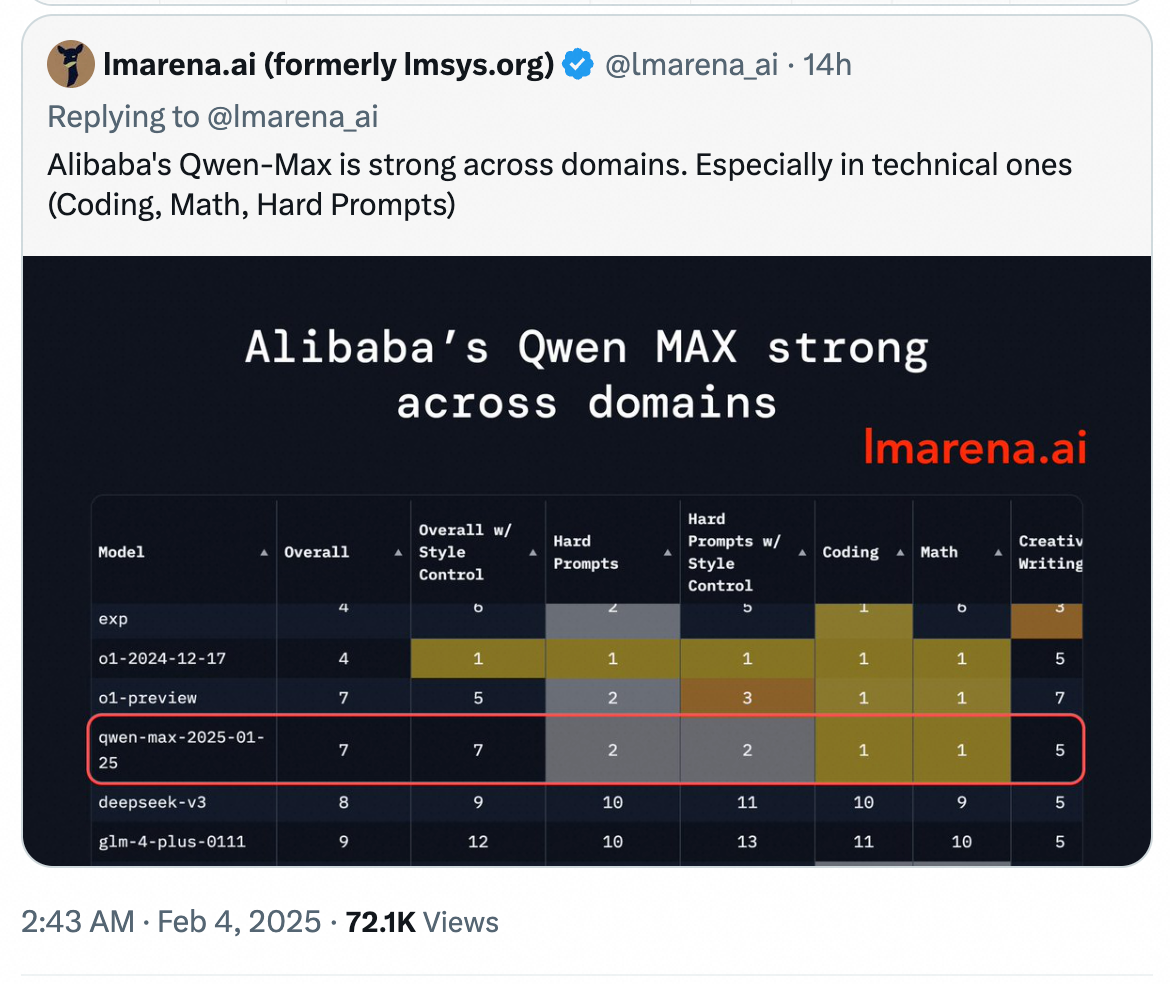 Qwen2.5-Max是阿里云通義團隊約一周前發(fā)布的最新MoE模型,展現(xiàn)出極強勁的性能。在Arena-Hard、LiveBench、LiveCodeBench、GPQA-Diamond及MMLU-Pro等主流基準測試中,Qwen2.5-Max比肩Claude-3.5-Sonnet,并幾乎全面超越了GPT-4o、DeepSeek-V3及Llama-3.1-405B。
Qwen2.5-Max是阿里云通義團隊約一周前發(fā)布的最新MoE模型,展現(xiàn)出極強勁的性能。在Arena-Hard、LiveBench、LiveCodeBench、GPQA-Diamond及MMLU-Pro等主流基準測試中,Qwen2.5-Max比肩Claude-3.5-Sonnet,并幾乎全面超越了GPT-4o、DeepSeek-V3及Llama-3.1-405B。
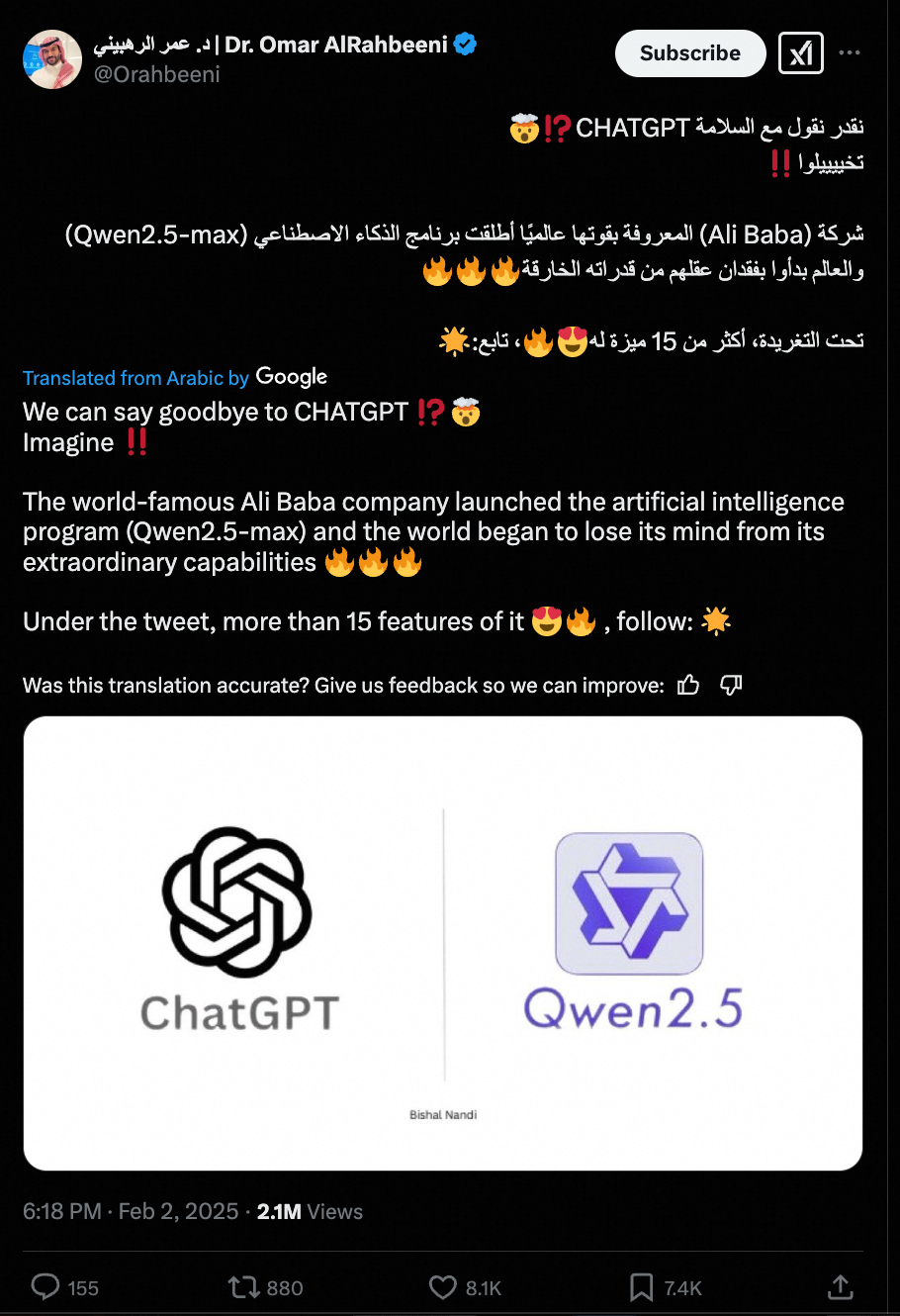
Qwen2.5-Max發(fā)布后,立刻在海內(nèi)外大模型社區(qū)引發(fā)熱議:ChatBot Arena官方發(fā)推文稱,以Qwen2.5-Max為代表的中國大模型正在迎頭趕上;有從業(yè)者在驚嘆新模型強大性能的同時,也興奮地表示:“我們可以告別ChatGPT了!”
目前,企業(yè)可在阿里云百煉調(diào)用Qwen2.5-Max模型的API服務,開發(fā)者也可在Qwen Chat平臺中免費體驗最新模型。
(完)
 京公網(wǎng)安備 11010802028547號
京公網(wǎng)安備 11010802028547號
 購物車
購物車






